
A critical region in statistics is the set of all values of a test statistic that leads to the rejection of the null hypothesis. It helps determine whether an observed effect is statistically significant.
Understanding critical regions is fundamental in hypothesis testing, a core concept within statistical analysis. This area denotes where the probability of finding the observed results is less than the significance level if the null hypothesis were true. Statisticians set these boundaries before collecting data to maintain the integrity of the test and control error rates.
The identification of a critical region depends on the chosen significance level and the test’s distribution, commonly the t-distribution or the normal distribution for many tests. Setting the correct critical region allows analysts to draw meaningful, data-driven conclusions with confidence. As such, clarity about this concept is crucial for any research where statistical validation is required.

Credit: www.datapine.com
The Essence Of Critical Regions In Statistical Hypothesis Testing
The essence of critical regions lies at the heart of statistical hypothesis testing. This concept helps us to draw conclusions from data, guiding our decisions about whether a scientific theory or assumption holds weight. By setting up criteria to test our hypotheses, critical regions act as a benchmark to decide if observed results are likely due to chance or if they signal a real effect. Navigating through statistical hypothesis testing without understanding critical regions is like trying to find a hidden treasure without a map; you know the treasure exists, but you won’t be able to find it without the proper guidance.
Distinguishing Type I And Type Ii Errors
Unpacking the errors in statistical testing, we stumble across two main villains: Type I and Type II errors. A Type I error occurs when we incorrectly reject a true null hypothesis; think of it as a false alarm. Conversely, a Type II error arises when we fail to reject a false null hypothesis—akin to a missed opportunity to spot something significant. Identifying and distinguishing these errors is critical for data analysts and researchers to maintain the integrity of their findings.
The Role Of Significance Levels
To navigate through the tricky landscape of statistical testing, significance levels act as our compass. These levels, often denoted by the symbol alpha (α), are the thresholds we set to determine how rare our data must be before we reject the null hypothesis. A commonly used significance level is 0.05, meaning there’s a 5% chance of committing a Type I error. With this pre-defined benchmark, analysts can confidently defend their decisions, understanding the balance between being too cautious and too impulsive when interpreting data.
| Error Type | Description | Consequences |
|---|---|---|
| Type I Error (False Positive) | Rejecting a true null hypothesis | False alarm; thinking something exists when it doesn’t |
| Type II Error (False Negative) | Failing to reject a false null hypothesis | Missed detection; not noticing something important |
- Setting a low significance level reduces the chance of a Type I Error.
- A high significance level could increase the risk of a Type II Error.
Selecting the appropriate significance level is akin to picking the right tool for a job. It shapes the critical region and thereby steers the course of the hypothesis test outcome. Experts must consider their threshold for risk and the context of their investigation when choosing the best significance level for their tests.

Credit: analystprep.com
Constructing And Interpreting Critical Regions
Understanding the heart of hypothesis testing begins with the Critical Region. This concept separates results that support the hypothesis from those that don’t. Let’s dive into the steps and considerations for constructing and interpreting these critical areas.
Selection Criteria For Critical Values
- Significance Level: Set the alpha value, which defines the probability of rejecting a true hypothesis.
- Test Type: Decide between a one-tailed or two-tailed test, based on research queries.
- Distribution Type: Identify the right probability distribution (normal, t-distribution, etc.) for the data set.
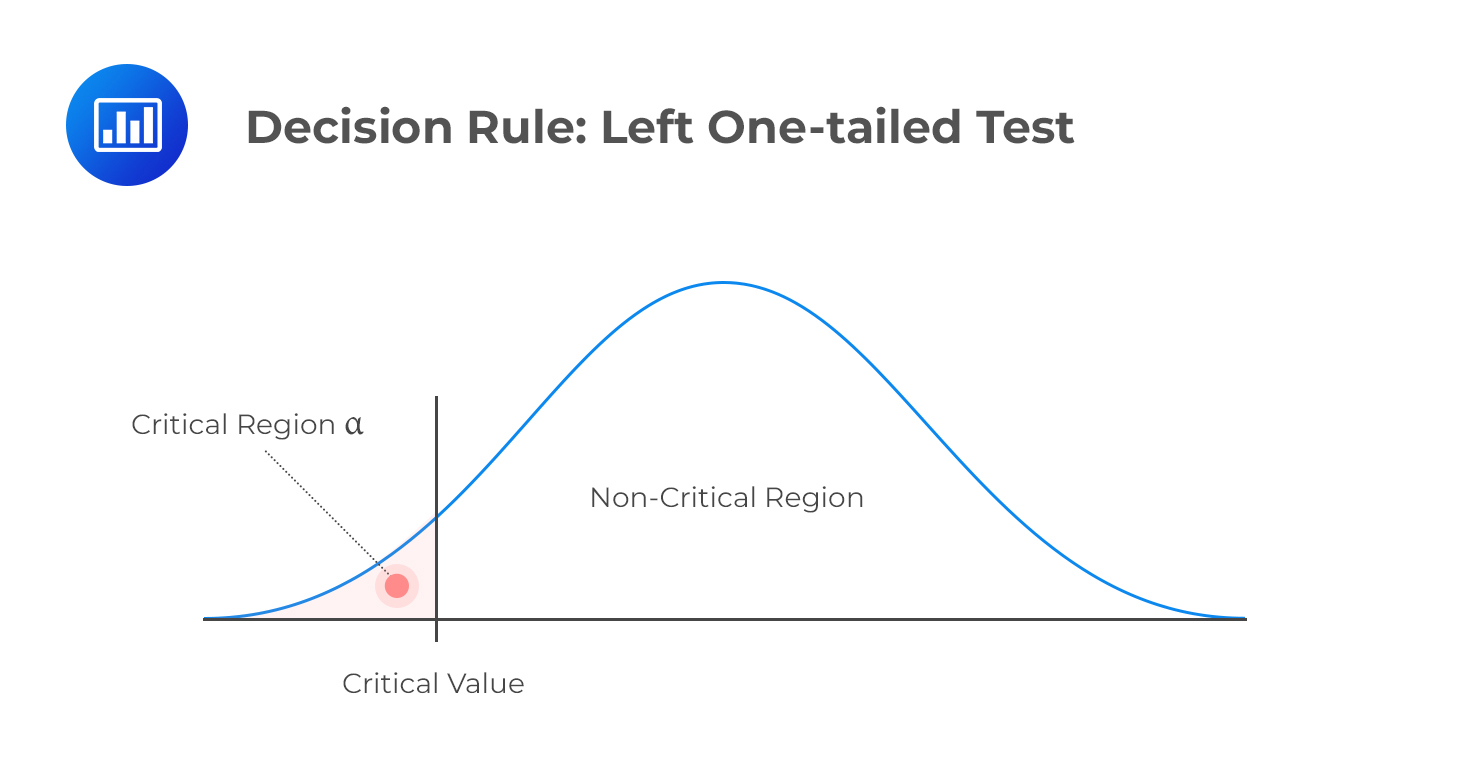
Visualizing Decision Boundaries With Probability Distributions
Probability distributions create a visual outline of data behaviors. Critical values form the edges where results can be ‘accepted’ or ‘rejected’.

| Result Area | Interpretation |
|---|---|
| Inside Critical Region | Reject Null Hypothesis |
| Outside Critical Region | Fail to Reject Null Hypothesis |
By mastering these elements, anyone can confidently construct and interpret critical regions in statistical analysis. Remember to keep your analysis precise and your data interpretation sharp.
Real-world Applications Of Critical Region Analysis
The power of critical region analysis in statistics stretches far beyond the classroom. In various sectors, understanding this concept is pivotal for making rational decisions based on data. Here’s a look at how critical regions play a vital role in our world.
Enhancing Decision-making In Clinical Trials
In the medical field, critical region analysis is a cornerstone. It helps scientists understand the effectiveness of new treatments. Let’s explore:
- Determining drug efficacy: By setting precise thresholds, researchers can conclude if a drug works or not.
- Minimizing risks: This statistical approach ensures patient safety remains the top priority.
- Speeding up approvals: Quick analysis of data speeds up the process of getting treatments to market.
Employing critical region statistics provides a clear path in the complex journey of drug development.
Driving Business Insights Through Market Research
Businesses rely on market research to make smart decisions. Here is how:
- They set boundaries to identify consumer trends.
- Ideas are tested against market expectations.
- Data drives strategies for product development and marketing.
With critical region analysis, companies gain useful insights, allowing them to stay ahead in the competitive business landscape.
Credit: analystprep.com
Frequently Asked Questions On Critical Region Statistics
How Do You Find The Critical Region In Statistics?
To find the critical region in statistics, determine the significance level (alpha), select the appropriate statistical test, and define the range of values that reject the null hypothesis based on the test’s probability distribution.
What Is The Critical Value In Statistics?
The critical value in statistics is a threshold that defines the boundary for the rejection of a null hypothesis in a statistical test. It helps determine whether a test result is statistically significant.
What Is 95% Critical Region?
The 95% critical region is an area on a statistical distribution where, if a test value falls within it, we reject the null hypothesis with 95% confidence.
What Is The Best Critical Region In Statistics?
The best critical region in statistics is one that maximizes power while maintaining a specified significance level, tailored to the hypothesis test at hand.
Conclusion
Understanding critical regions is pivotal for interpreting statistical outcomes effectively. It shapes our approach to hypothesis testing and decision-making within data analysis. As we’ve dissected the concept, always remember: proper identification of critical values bolsters the reliability of your statistical inferences.
Mastery of this topic can significantly upgrade your analytical prowess, leading to more accurate and compelling insights. Stay curious and keep refining your statistical toolkit for continued success in research and beyond.